
Autonomous Vehicle Visual Control in Simulation
Overview
This project models the dynamics of a standard self-driving car and implements controls for the motion of the vehicle using perception capabilities provided by CARLA. We discuss a control implementation in CARLA, including a PID controller for throttle and steering control as well as a higher level visual control model that uses image and lidar data to provide waypoint and velocity targets for the PID controller. This project builds off of the state-of-the-art in visual control in CARLA, Transfuser++.
The code for this project can be found here.
Control
The base controller used for waypoint following consists of longitudinal and lateral PID controllers, which provide throttle, brake, and steering inputs to the vehicle to reach specified target speeds and waypoints. The structure of this controller setup can be seen below.

This project utilizes both image and lidar sensors mounted on the vehicle in CARLA in order to perform visual-based control and adjacent perception tasks. The neural network, based on the work of TransFuser++, is designed to take in a single RGB image, a lidar birds-eye-view (BEV) image, the vehicle’s current speed, and a local waypoint as input. It then predicts a trajectory, consisting of target points and target speeds, to reach the local waypoint. A sample RGB image and lidar BEV image are shown below.


Transfuser++ performs early fusion with image and lidar data through a transformer-based backbone as seen in the architecture below.
![]()
This backbone performs a multi-modal fusion between the image and lidar feature maps at multiple resolutions throughout the feature extractor. The outputted feature vector from this backbone is then used for downstream tasks such as planning, depth estimation, semantic segmentation, object detection, etc. Because the model is trained on these auxiliary tasks, the feature extractor learns to encode extremely relevant information in the feature vector. The model uses this feature vector to predict goal velocities and waypoints. The entire TransFuser++ model architecture can be seen below, which shows the Transfuser backbone and waypoint/target speed prediction networks as well as the auxiliary prediction heads.

Improvements
TransFuser++ shows impressive performance while only using a single camera and beats all of the competing models, many of which use multiple cameras. However, in a real-world scenario, relying on a single camera is risky and is prone to a number of potential issues. To remedy this, we modify TransFuser++ to handle multiple cameras and be robust to potential disturbances to individual cameras. For example, the model is robust to parts of the camera being covered by debris as well as general image noise you may see in the real world.
To make these improvements, we create an agent that sets up three cameras on the front of the vehicle. One facing straight ahead, and two cameras angled left and right at an angle of 30 degrees. We found that the best method of using the additional image data was to stack the images vertically and fine-tune an existing model to learn the redundancy in image information. Additionally, we introduce several different types of noise to the images to introduce some regularization into the model such that it is robust to disturbances to individual cameras. To add random image noise that may occur in cameras due to a number of reasons such as circuit nosie or low-light conditions, we randomly add gaussian, poisson, and salt & pepper noise to the images with some probability. We also change the image exposure in order to introduce robustness to badly calibrated cameras. Finally, to ensure that the model takes advantage of the redundancy encoded in the right and left image overlap with the main front camera, random patches of the images are made to be completely black to mimic debris covering the camera. Some examples of the noisy images are shown below

Results
We fine-tune a pretrained Transfuser++ model by simultaneous evaluating two Transfuser++ models: one functions as the supervisory model, receiving single camera and lidar input (as the original model was designed), while the other serves as the trainable model, receiving three cameras and lidar input. Hence, through imitation, the trainable model can learn to relate and extract extra image information for downstream trajectory and speed predictions. We conduct training in five CARLA worlds, with 280 unique routes and random weather as well as the added random noise. Qualitative comparisons for the models are shown below.
 Transfuser++ w/ no noise Transfuser++ w/ no noise |  Transfuser++ w/ noise Transfuser++ w/ noise |
 Ours w/ no noise Ours w/ no noise |  Ours w/ noise Ours w/ noise |
Additionally, we compare the models on several metrics: Route completion percentage (RC), Collision count (CC), and Lane invasion frame count (LI).
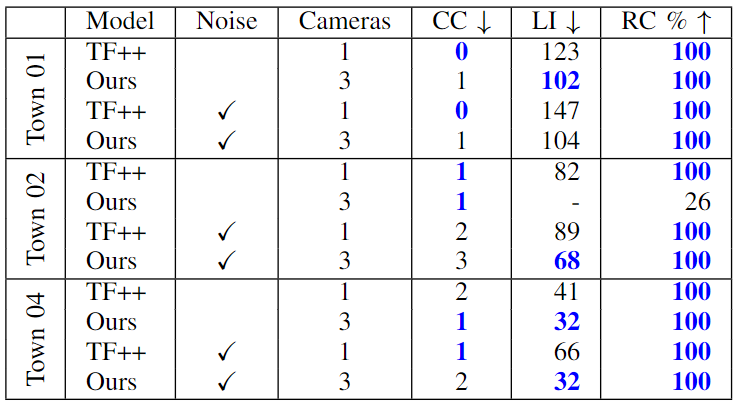
The results in the table above show that the fine-tuned model is generally better at staying in lane than the original Transfuser++ model in the presence of noise. Based on our observations from the experiments, the fine-tuned model sometimes struggles to identify and respond to objects such as traffic lights and mailboxes, resulting in unstable performance. We believe this flaw can be attributed to the amount of training. Due to computation resource limitations, we were only able to train on 280 routes with no repetitions, compared to the original model’s 1700+ routes with repetitions. Additionally, using the original model as ground truth for training places limitations on the performance potential our model can achieve. We believe there is potential for greater improvements with more training and access to a better ground truth trajectory.
A full run of a vehicle running our trained model can be seen below.